Stock sentiment analysis and consumer sentiment analysis are relatively new […]
How we discover (and confirm) brand/product keywords
February 6, 2021
At LikeFolio, we have a love/love relationship with our social data. We know to make consumer insights valuable to companies and investors, we need to carefully curate and nurture data.
With such a large data sample size (over 500 million tweets a day) we have a HUGE base to sift through to create value. How do we do it? Peek into our research lab….
Step 1: Discoverability Testing
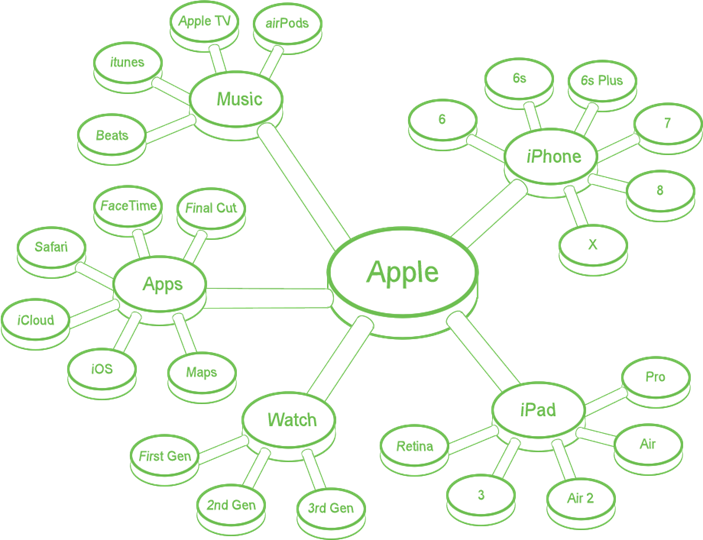
After all brands and products are identified, it’s time to dive into Twitter. Scanning tweets for mentions of “Facebook” is cake. Quickly spotting mentions of “Apple” is a different ballgame. A query for “Apple” will reveal tweets about the company, the snack, the childhood board game, and plenty of colloquialisms.
For data to have value for Apple (the company), we need to isolate ONLY mentions of Apple brands, products and services. This requires a mix of Boolean logic and custom keywords.
Step 2: Natural Human Language Application
How do consumers talk about brands and products? Not necessarily how are they supposed to speak about products (“Apple Watch Series 4”), but how do people actually speak about using products and services (“closed my rings”).
Insider tip: not all consumers are experts in grammar, spelling, or formal product names. We search Twitter and use real talk to create thousands of custom keywords to build the largest and most accurate sample size possible for each brand and product within a company.
Step 3: Tweet Sample Analysis
After we’ve identified all potential custom phrases for a company, we test them again with extensive tweet samples and human analysis. Really, our team of humans reads THOUSANDS of tweets. We make small tweaks to our own logic to refine our data sample when warranted and eliminate any non-consumer and non-brand related activity.
Step 4: Data Integrity Check
Once initial data is aggregated, we review tweets on high-volume dates. We annotate each of these dates on the dashboard to provide an explanation for cause of high volume and allow for a “correction” on the dates we feel may be media, marketing or politically related.
We allow Research Dashboard users to turn corrections on and off instead of eliminating these mentions entirely because the conversations can still be relevant indicators for a company.
Step 5: Repeat
When our data gets a final stamp of approval, it doesn’t stop growing. We are constantly scanning for shifts in how consumers discuss brands and products and track all new product releases.
We update each company on a regular basis (bimonthly) to keep our data up to speed and predictive.
Comparing Apples to Apples (see what I did there)
Our methodology ensures accuracy but also means that sometimes we produce a much smaller sample size for companies with brands and products that aren’t easily discoverable vs. companies with brands and products with unique names.
So, a company’s raw mention volume should only be compared against itself – that’s where the relevant trend/change is revealed. For comparisons between brands/products, we suggest looking at rates of change in each dataset to see which companies/brands/products are gaining (or losing) the most traction with consumers.